客户端 timewait 过多解决方案
本文背景
客户压测 CLB 时,常会遇到一些客户端 timewait 过多,端口被快速占满,导致 connect 失败的问题,下面会说明原因和解决方案。
Linux 参数介绍
- tcp_timestamps:是否开启 tcp timestamps 选项,timestamps 是在 tcp 三次握手过程中协商的,任意一方不支持,该连接就不会使用 timestamps 选项。
- tcp_tw_recycle:是否开启 tcp time_wait 状态回收。
- tcp_tw_reuse:开启后,可直接回收超过1s的 time_wait 状态的连接。
原因分析
客户端 timewait 太多,是因为客户端主动断开连接,客户端每断开一个连接,该连接都会进入 timewait 状态,默认60s超时回收。一般情况下,遇到这种场景时,客户会选择打开 tcp_tw_recycle 和 tcp_tw_reuse 两个参数,便于回收 timewait 状态连接。然而当前 CLB 没有打开 tcp_timestamps 选项,导致客户端打开的 tcp_tw_recycle 和 tcp_tw_reuse 都不会生效,不能快速回收 timewait 状态连接。下面会解释几个 Linux 参数的含义和 CLB 不能开启 tcp_timestamps 的原因。
-
tcp_tw_recycle和tcp_tw_reuse只有在tcp_timestamps打开时才会生效。 -
tcp_timestamps和tcp_tw_recycle不能同时打开,因为公网客户端经过 NAT 网关访问服务器,会存在问题,原因如下:tcp_tw_recycle和tcp_timestamps都开启的条件下,60s内同一源 IP 主机的 socket connect 请求中的 timestamp 必须是递增的。以2.6.32内核为例,具体实现如下:
tmp_opt.saw_tstamp:该 socket 支持 tcp_timestamp。sysctl_tw_recycle:本机系统开启 tcp_tw_recycle 选项。TCP_PAWS_MSL:60s,该条件判断表示该源 IP 的上次 tcp 通讯发生在60s内。TCP_PAWS_WINDOW:1,该条件判断表示该源 IP 的上次 tcp 通讯的 timestamp 大于本次 tcp。
-
CLB(7层)关闭了
tcp_timestamps原因,因为公网客户端经过 NAT 网关访问服务器,可能会存在问题,如下例:- 某五元组还是 time_wait 状态。NAT网关对端口的分配策略,2MSL内复用了同个五元组,发来 syn 包。
- 在开启
tcp_timestamps情况下,同时满足如下两个条件,会丢弃该 syn 包(因为开启了时间戳选项,认为是老包): i. 上次时间戳 > 本次时间戳。 ii. 24天内收过包(时间戳字段是32位,Linux 默认1ms更新一次时间戳,24天会发生时间戳回绕)。 备注:在移动端该问题更为明显,因为客户端都是在运营商 NAT 网关下面共享有限的公网 IP,五元组还可能在2MSL内被复用,不同客户端传来的时间戳不能保证是递增的。 以2.6.32内核为例,具体实现如下: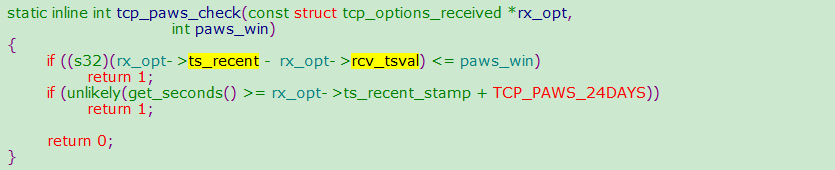
rx_opt->ts_recent:上次的时间戳rx_opt->rcv_tsval:本次收到的时间戳get_seconds():当前时间rx_opt->ts_recent_stamp:上次收到包的时间
解决方案
客户端 Timewait 过多问题,有如下解决方案:
- HTTP 使用短连接(
Connection: close),这时由 CLB 主动关闭连接,客户端不会产生 timewait。 - 如果场景需要使用长连接,可以打开 socket 的
SO_LINGER选项,使用 rst 关闭连接,避免进入 timewait 状态,达到快速回收端口的目的。